
Outline
Introduction
We continue our tutorial on Deep Learning with LabVIEW.
In the previous blog post, we spoke about neural network logistic regression with a single output. Now we are going to examine the logistic regression with multiple outputs and we will model Boolean adder with help of DeepLTK (Deep Learning Toolkit for LabVIEW) in LabVIEW.
As we know the logistic regression is a statistical approach utilized for binary classification tasks, where the target variable has only two categorical values (e.g., 0 or 1). The logistic regression simply models probability of output in terms of inputs.
In this article, we will explore the multi-output logistic regression model and its application in solving the Boolean Adder problem. Particularly calculating the sum of two 8-bit integers. Here each input and output is being represented as 8 separate binary values, meaning predicting 8 binary outputs based on 16 binary inputs.
It is important to note that this problem (of performing binary addition) is not a classification problem. In classification the model predicts to which class the inputs falls to, while here we are predicting a probability for each 8 outputs separately. This problem could also be considered as having 8 models trying to solve binary classification for each output separately.

By employing DeepLTK we aim to build a model which will be able to predict the sum of two integers.
If you are not familiar with the basics of using DeepLTK, we recommend reading the previous article (Deep Learning with LabVIEW. Tutorial #1.1: Simple Logistic Regression - Boolean Operations)
This and other DeepLTK based LabVIEW examples can be accessed from our GitHub page.
The project consists of two main VIs: one for model training and the other for assessing the neural network's performance during the inference.
Training: 1_Boolean_Adder(Training).vi
Front Panel of Training VI
Below is a snapshot or the training VI, we are going to use in this tutorial.

For detailed information on the contents of front panel and configuration parameters please refer to previous blog post's Front Panel of Training VI section.
In this particular example we have included additional metric called Error Rate, which will be explained later.
Block Diagram of Training VI
The block diagram of the example is show below.

Here the network has following configuration (Input(16) --> FC(128) --> FC(128) -->FC(8)). The size of the input is chosen to accommodate binary values from two integer inputs. The size of last FC(Fully Connected) layer is chosen, so it can represent the predicted values, i.e. 8 binary values of addition operation.
Minibatch size is chosen 64 and MSE(Mean Square Error) as the loss function.
For activation functions, we apply the LReLU (Leaky Rectified Linear Unit) for the hidden layers and the Sigmoid function for the output layer, providing the probabilities of predictions.
For more information about the details of the Block Diagram of training VI, please refer to the previous blog post.
Dataset Generation
Let's now see how we can generate a dataset for this task. Below is a snippet of code responsible for that.
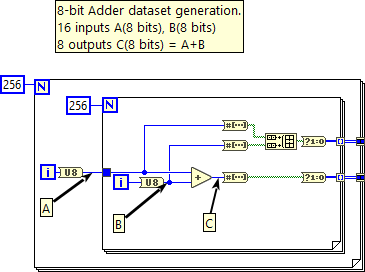
First we assume that the inputs and the outputs are unsigned 8-bit integers (U8 in LbVIEW).
With two nested loops we generate all possible combinations of the inputs and their corresponding output, i.e. the sum, which range from 0 to 255. Then we extract their binary representations and convert Boolean values to 0 and 1. These numeric values will represent the inputs and expected numeric values at the output of the network.
Observe the visual representation below for a better understanding:

Model Evaluation - Calculating the Error Rate
To evaluate the model's performance we are interested in its Error Rate, which represents the percentage of incorrectly predicted samples in the dataset.
Let's look at the block diagram of the code calculating the Error Rate.

To get the actual predicted value at the output represented as integer, we first need to threshold all outputs of the network with the center of the range, i.e. 0.5. Predictions above 0.5 are assigned as 1 (TRUE), while those below 0.5 are marked as 0 (FALSE). The thresholder values represent the bits of the output, which after combining together can be converted into an integer. The same operations are performed over the ground truths. Once we have our predictions and ground truth represented as numbers we can easily compare them for equality. Then the Error Rate is calculated as the number of incorrect predictions divided over the size of the dataset.
Training the Network
Lets run the training VI. During the training we observe the Loss and Error Rate curves. The loss function is an indirect metric showing how close are each predicted output of the network to the target output (1 or 0). In general it is used to observe how the model is performing during the training, meanwhile the Error Rate is the final metric we are interested in, as it shows what portion of dataset has been incorrectly predicted by the model. After running the VI we can see that the Loss and Error Rate start to decrease. One can see that with the chosen configuration of the model and hyperparameters it is possible to achieve 100% of accuracy, i.e. 0% of Error Rate.
Note: It might require to run the training process couple of times, until the model converges to 0 error rate state, as some times the model can stuck in one of the local minimums. If the network fails to train (loss gets stuck at high values), stop the VI’s execution by pressing the Stop Train button and restart the training process.

As explained above, the Loss might not be able to reach exact 0 value, but the Error Rate can. The reason is that the outputs of the network are continuous values, and the Loss is calculated based on this values, meanwhile the Error Rate is based on quantized versions of the outputs.
Inference: 2_Boolean_Adder(Inference)
Block Diagram
Below is snapshot of inference VI, which shows how the numeric inputs are converted before being fed to the network, and how the predicted values are reinterpreted to represent the prediction in numeric format.

Front Panel
Now lets test the trained model on some samples to visually evaluate its performance.
For the detailed information about the front panel and block diagram of the inference vi, please refer to the previous blog post Inference section.
Summary
In this blog post, we explore logistic regression with multiple outputs. Here we demonstrated how DeepLTK can be used for creating, training and evaluating the performance of a neural network model on 8-bit adder problem.
Things to Do Next
To strengthen the knowledge, we suggest readers to solve the following similar problems based on the reference example.
It is rule of thumb that the models performance should be evaluated on "Test" dataset, which basically contains similar samples of inputs and outputs, but which should be different from the "Training" dataset. As the number of samples in 8-bit adder is limited to 65,536=256*256, we can use all possible values that might appear during deployment of the network in our training, and use the same for testing. But if we consider 16-bit adder case, this might not be feasible to implement on common PC, as the number of possible inputs reaches ~4 billions. If we assume that we have 32 inputs with SGL (float32) with 4 bytes each, this would require ~512 of RAM to store only inputs of the dataset, and half of that for the outputs.
So, as it usually happens with images, or other real world sources, we train a model on smaller portion of possible inputs (Training dataset), and evaluate it on another portion (Test dataset).
We propose our readers to implement a 16-bit adder based on this reference example.
Comentarios